Overview
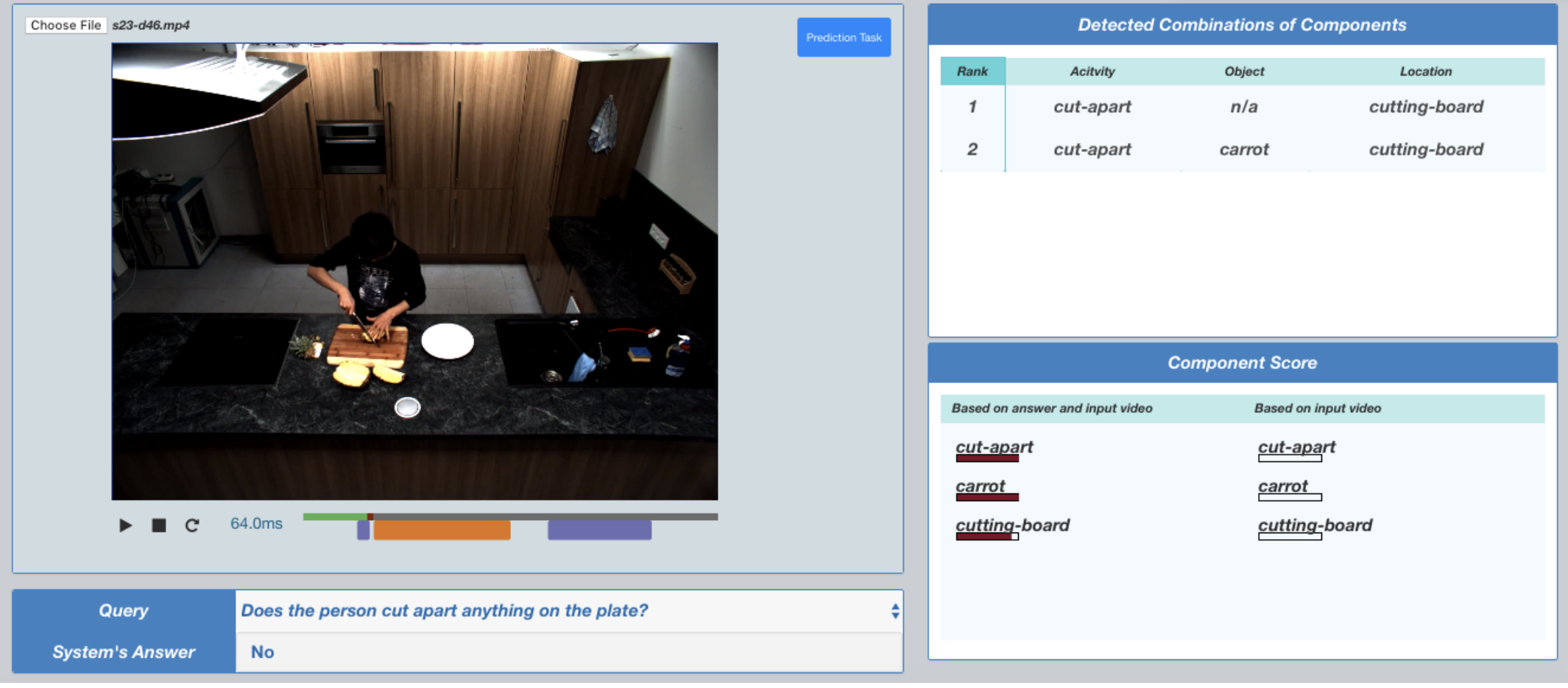
Although activity recognition in videos can be solved accurately using existing deep learning systems, their use is problematic in interactive settings. In particular, deep learning models are black boxes: it is difficult to understand how and why the system assigned a particular activity to a frame. This reduces the users’ trust in the system, especially in the case of end-users who need to use the system on a regular basis.This problem is addressed by feeding the output of deep learning to a tractable interpretable probabilistic graphical model and then performing joint learning over the two. The key benefit of this proposed approach is that deep learning helps achieve high accuracy while the interpretable probabilistic model makes the system explainable. The power of this approach is demonstrated using a visual interface to provide explanations of model outputs for queries about videos.